

Chemistry is more than just mixing compound A with compound B to make compound C. There are catalysts that affect the reaction rate, as well as the physical conditions of the reaction and any intermediate steps that lead to the final product. If you’re trying to make a new chemical process for, say, pharmaceutical or materials research, you need to find the best of each of these variables. It’s a time-consuming trial-and-error process.
Or, at least, it was.
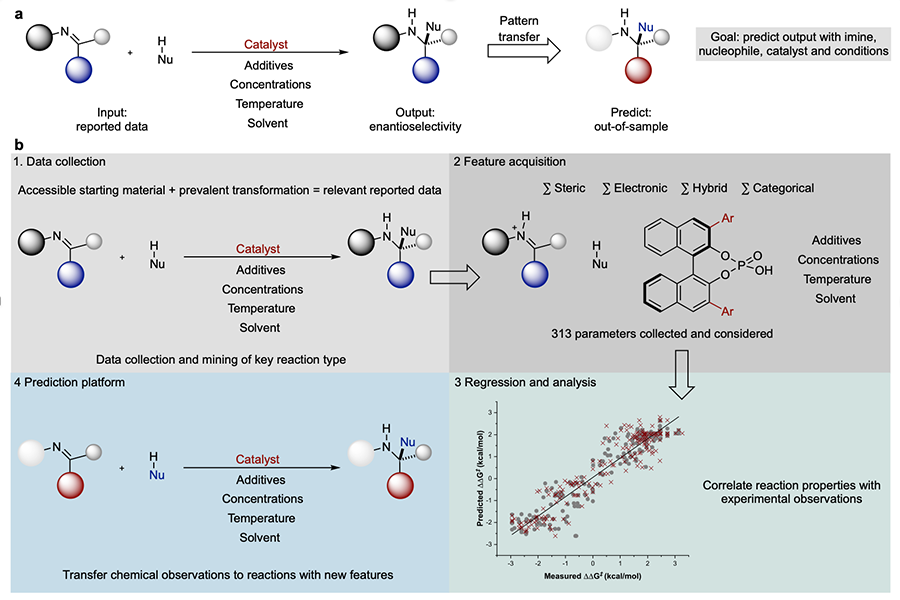
In a new publication in Nature, University of Utah chemists Jolene Reid and Matthew Sigman show how analyzing previously published chemical reaction data can predict how hypothetical reactions may proceed, narrowing the range of conditions chemists need to explore. Their algorithmic prediction process, which includes aspects of machine learning, can save valuable time and resources in chemical research.
“We try to find the best combination of parameters,” Reid says. “Once we have that we can adjust features of any reaction and actually predict how that adjustment will affect it.”
Trial and error
Previously, chemists who wanted to carry out a reaction that hadn’t been tried before, such as a reaction to attach a particular small molecule to a particular spot on a larger molecule, approached the problem by looking up a similar reaction and mimicking the same conditions.
“Almost every time, at least in my experience, it doesn’t work well,” Sigman says. “So then you systematically change the conditions.”
But with several variables in each reaction—Sigman estimates around seven to 10 in a typical pharmaceutical reaction—the number of possible combinations of conditions becomes overwhelming. “You cannot cover all of this variable space with any type of high throughput operation,” Sigman says. “We’re talking billions of possibilities.”
Narrowing the field
So, Sigman and Reid looked for a way to narrow the focus to a more manageable range of conditions. For their test reaction, they looked at reactions that involve molecules with opposite mirror images of each other (in the same way your right and left hands are mirror images of each other) and that select more for one configuration than another. Such a reaction is called “enantioselective”, and Sigman’s lab studies the types of catalysts involved in enantioselective reactions.
Reid collected published scientific reports of 367 forms of reactions involving imines, which have a nitrogen base, and used machine learning algorithms to correlate features of the reactions with how selective they were for the two different forms of imines. The algorithms looked at the reactions’ catalysts, solvents and reactants, and constructed mathematical relationships between those properties and the final selectively of the reaction.
“There’s a pattern hidden beneath the surface of why it works and doesn’t work with this condition, this catalyst, this substrate, and so on,” Sigman says.
“The key to our success is that we use information from many reactions,” Reid adds.
Easing the pain
How well does their predictive model work? It successfully predicted the outcomes of 15 reactions involving one reactant that wasn’t in the original set, and the outcomes of 13 reactions where both a reactant and catalyst type were not in the original set. Finally, Reid and Sigman looked at a recent study that conducted 2,150 experiments to find the optimal conditions of 34 reactions. Without dirtying a single beaker, Reid and Sigman’s model arrived at the same results and same optimal catalyst.
Reid looks forward to applying the model to predicting reactions involving large, complex molecules. “Often you find that new methodologies aren’t fine-tuned to complex systems,” she says. “Possibly we could do that now by predicting beforehand the best kind of catalyst.”
Sigman adds that predictive models can lower the barriers to new drug development.
“The pharmaceutical industry doesn’t want to invest money into something that they don’t know if it’s going to work,” he says. “So, if you have an algorithm that suggests this has a high probability of working, you ease the pain.”
Find the full study here.